pip install pycaret
import pandas as pd
// sample.xlsxというExcelの sheet1 のデータを読み込む
df = pd.read_excel('sample.xlsx', sheet_name='sheet1', index_col=0).reset_index()
df = df.fillna('')
X = df.copy()
// 回帰
from pycaret.regression import *
// Xというデータを機械学習にかける
// 列名 _y が結果(目的変数)
// 列名 ix, c は学習では無視 *参考までに
ret = setup(X , target = "_y" , ignore_features=['ix', 'c'], session_id=0 , normalize = False , train_size = 0.8 )
//models()
//たくさんあるアルゴリズムで評価
compare_models(sort="R2", fold=10)
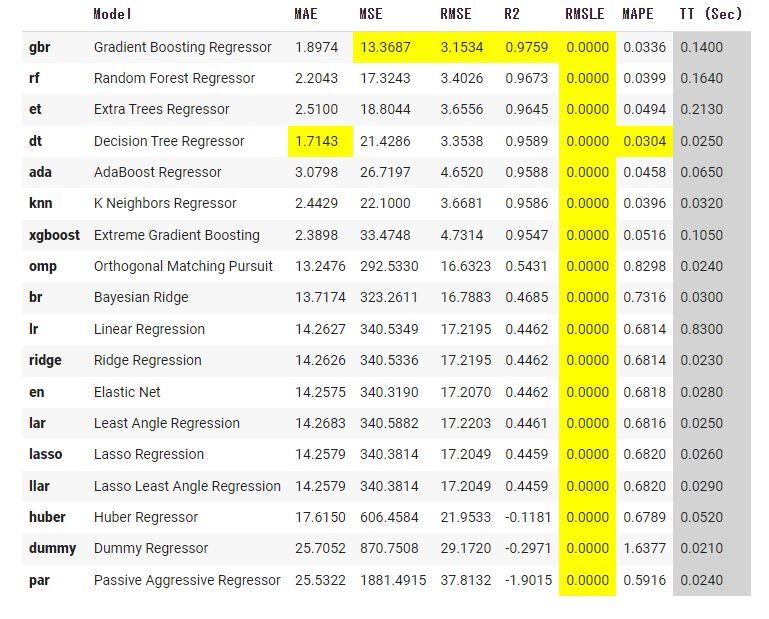
// モデルはGBRを用いる(一番精度がよさそう)
rf = create_model("gbr", fold = 10)
// モデルをチューニング
tuned_rf = tune_model(rf, optimize = "r2", fold = 10)
// 以下で性能などを見ることができる
evaluate_model(tuned_rf)
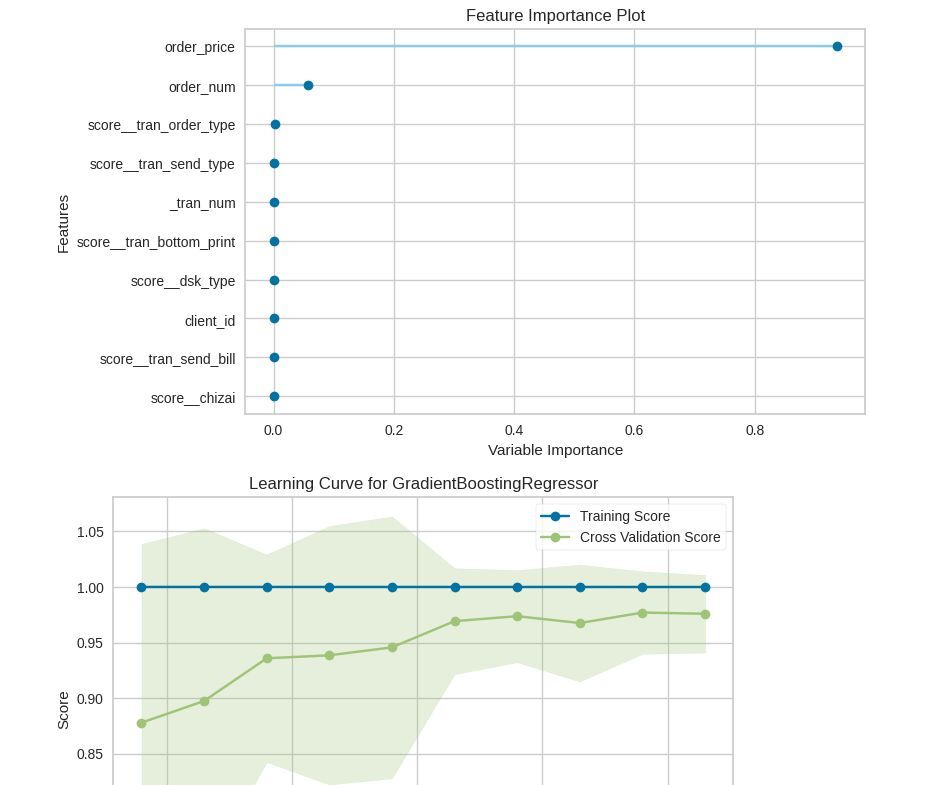
plot_model(tuned_rf, "feature")
plot_model(tuned_rf, "learning")
plot_model(tuned_rf, "error")
final_rf = finalize_model(tuned_rf)
X_csv = df.copy()
// 学習・チューニングしたモデルで予測
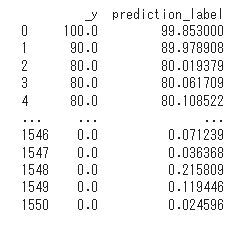
ret_df2 = predict_model(final_rf, data=X_csv)
// CSV に出力する例
//ret_df2.to_csv("ret_df3.tsv", sep='\t')
print(ret_df2)
from pycaret.regression import *
| 回帰 | pycaret.regression |
|---|---|
| 分類 | pycaret.classification |
| クラスタリング | pycaret.clustering |
| 異常検知 | pycaret.anomaly |
| 自然言語 | pycaret.nlp |
| アソシエーションルールマイニング | pycaret.arules |
// 回帰の場合 ↓↓↓ from pycaret.regression import * // 分類の場合 ↓↓↓ from pycaret.classification import *
